Elevating Stability in Financial Success
Blog

05 December
2025
Feature Engineering - Best practices for building high-performance models, be it prediction or forecasting
Introduction
Feature engineering is a systematic process designed to identify and select the most effective set of features for building a strong predictive model. Including too many features, especially those that are highly correlated, can lead to model underperformance or overfitting. In many cases, the Pareto principle (the 80/20 rule) applies: roughly 80% of a model’s predictive power can often be attributed to just 20% of its features. This highlights why thoughtful and disciplined feature engineering is crucial in developing high-performing AI or predictive models.
In this blog, we will focus specifically on structured data, which follows a clear schema. The other two types of data, semi-structured (with a loose schema) and unstructured (with no schema) require different approaches. For those, techniques such as text analytics and sentiment analysis are commonly used to extract meaningful features that can then be incorporated into predictive modeling.
Feature Engineering
Feature engineering consists of four key processes: extraction, transformation, learning, and selection. Beginning with raw data, these steps are applied sequentially to produce a dataset of features and corresponding labels—where each instance (row) of data is assigned a label that can be used to train a machine learning algorithm. As illustrated in Figure (1), the process is both sequential and iterative; even after an initial round of feature selection, additional features can be extracted from the data repository and refined through subsequent iterations. In the following sections, we explore each of these four sub-processes in greater detail.
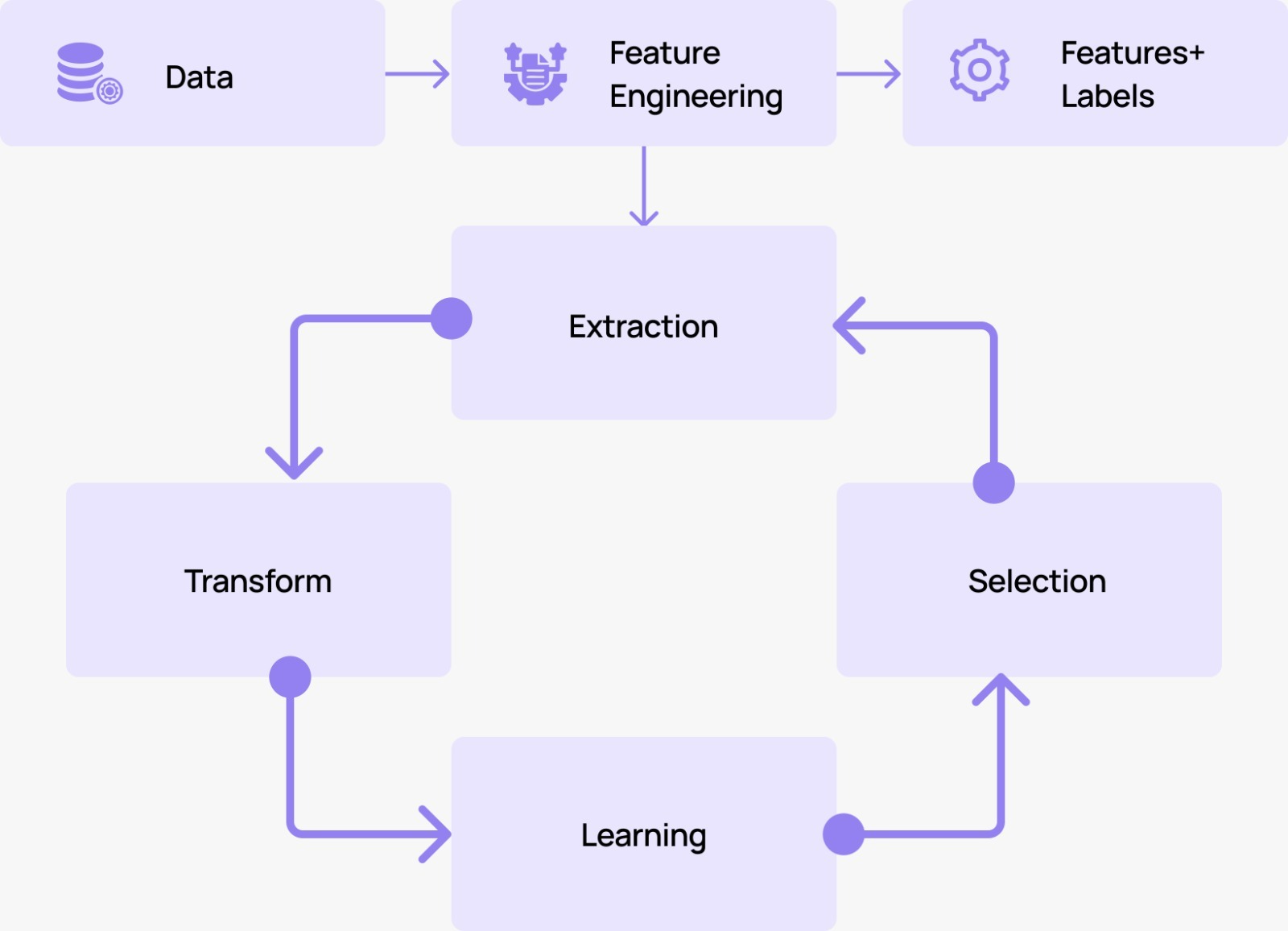
1.Feature Extraction
Before beginning the journey of building an AI or ML model for prediction, it is essential to first assess the data available. In many cases, data is scattered across multiple systems rather than stored in a single centralized repository. To address this, a well-defined data migration process must be established to ensure all data is easily accessible and consistent. This migration should unify information from diverse sources into a centralized storage solution like a data warehouse, data lake, or lakehouse.
With a centralized data system in place, we can move on to the first step of feature engineering: feature extraction. Because feature engineering is an iterative process, it isn’t always necessary to extract every feature in the first pass. However, in many practical situations, all available features in the centralized repository are extracted at once to establish a complete baseline.
A crucial aspect of the feature extraction stage is the association of each data instance (or row) with a corresponding label. This label also known as the “ground truth” is essential for evaluating the effectiveness of the feature engineering pipeline. Although no AI or ML model is built during this phase, the inclusion of labels allows for detailed analysis and informed decisions regarding which features should ultimately be retained for model training.
At this stage, it is important to note that feature engineering can also be applied to forecasting tasks, where we analyze raw time series data to generate optimal predictive features even in the absence of explicit labels. These features may include lag features (past values), rolling window features (summary statistics over a moving window), time-based features (such as day of the week, month, or holidays), and external factors (like macroeconomic indicators or weather conditions) , mostly leading ones. Incorporating such features enhances model accuracy by enabling it to capture complex patterns, underlying trends, and seasonality within the data.
2.Feature Transformation
The second sub-process of feature engineering is known as feature transformation. This step involves modifying the original features in the centralized data system so they can be effectively used to build an AI or ML model. Raw data rarely exists in a form that is immediately suitable for modeling, so transformation ensures that the features are standardized, meaningful, and aligned with the requirements of the chosen algorithms.
To understand this better, it helps to recognize that features generally fall into three main types: numerical, categorical, and ordinal. Numerical features take on numeric values, while categorical features are typically represented as text strings. Ordinal features appear similar to categorical ones but have an inherent order among their values. For example, a feature with the values Good, Average, and Bad has a natural ranking that distinguishes it from purely categorical data.
For numerical features, common transformation techniques include scaling, which can be achieved through normalization or standardization. In normalization, each value is divided by the range (the difference between the maximum and minimum values), producing values between 0 and 1 if all are positive. Standardization, on the other hand, involves subtracting the mean and dividing by the standard deviation, resulting in data with a mean of zero and a standard deviation of one. Another frequently used transformation is the log transformation, which helps to reduce skewness in data distributions.
Categorical features are typically transformed using encoding, such as one-hot encoding, which converts text labels into binary indicator variables. When categorical variables have many distinct values, a bucketing technique can be used to group less frequent categories into a general class like “Other.” For ordinal features, encoding is simpler because their natural ordering allows them to be directly mapped to numerical values—for instance, assigning 0 to Good, 1 to Average, and 2 to Bad preserves the inherent order.
Finally, one of the most universally applicable transformation techniques across all feature types is imputation, which involves filling in missing or incomplete values. Imputation ensures that the dataset remains complete and consistent, preventing the loss of valuable data during model training and improving the overall robustness of the predictive pipeline.
3.Feature Learning
This sub-process is optional and involves the use of an AutoML (Automated Machine Learning) workflow. Traditionally, the entire feature engineering process can be performed manually, where domain experts determine which features to extract, what transformations to apply, and which features to ultimately select for the AI or ML model. This manual approach relies heavily on subject-matter expertise and detailed analysis of the underlying feature values to identify those that contribute most to model performance.
However, modern automated workflows now offer end-to-end solutions that include automated feature engineering (AutoFE). In this approach, unsupervised techniques analyze all extracted feature values and apply statistical and data-driven methods to identify the most relevant and predictive features. AutoFE can significantly accelerate the modeling process, reduce human bias, and enhance consistency across iterations, while still allowing domain experts to validate and fine-tune the results.
It is evident that automated feature engineering (AutoFE) is highly scalable, although it may demand substantial computational resources. It proves particularly effective for large datasets where the initial set of features is extensive, making manual feature engineering impractical and time-consuming. Nevertheless, manual feature engineering retains important advantages. It leverages domain knowledge, which is crucial in certain data transformation tasks—such as aggregation—where data points are grouped and summarized through statistical measures. Perhaps the most significant strength of manual feature engineering lies in the creation of interaction terms that combine two or more existing features. Without domain expertise, this process becomes infeasible due to the combinatorial explosion of possible feature interactions, a challenge that AutoFE cannot yet address efficiently. Manual feature engineering is also valuable when applying encoders, such as one-hot encoding, to convert categorical data into numerical form, where certain categorical values may be grouped to enhance the efficiency of the modeling process. Additional benefits of manual feature engineering include greater interpretability, stemming from its basis in expert knowledge, and improved interoperability across analytical workflows.
4.Feature Selection
In this sub-process, the final set of features (along with their corresponding labels) is determined for use in the AI or ML model. This stage is guided by rigorous statistical analysis, ensuring that only the most informative and relevant features are retained. Several key metrics and techniques are commonly employed to evaluate and refine feature sets. They include Information Gain, Gini Index, Correlation Analysis and Principal Component Analysis (PCA).
Together, these methods ensure that the final feature set is both efficient and predictive, laying a solid foundation for building robust and high-performing AI/ML models.
Conclusions
We have explored the best practices that underpin feature engineering, a crucial process that ensures an AI or ML model is trained on the most relevant and high-quality data available. In general, feature engineering is an iterative process composed of four key sub-processes: extraction, transformation, learning, and selection. Each of these steps refines the data further, improving its suitability for modeling.
By adhering strictly to this structured workflow, data scientists and engineers can maximize the predictive power and reliability of their models. Effective feature engineering not only enhances model performance but also lays a strong foundation for successful real-world deployment, where data quality and relevance are critical to achieving meaningful, actionable insights.






.png)

